지난 시간에 인덱싱, loc과 iloc의 차이점에 대해 다루었습니다.
이번에는 파생변수를 생성하고 변수명을 변경하는 방법을 보여드리고자 합니다.
대방에 쓸 물건들이 있는데 실제 업무에 많이 사용되는 것으로 여겨진다.
나는 단순히 pandas를 통해 데이터 프레임 df를 만들었습니다.
‘a1’과 ‘a2’는 값을 변수로 갖는다.

‘a1’과 ‘a2’를 결합하여 ‘a3’을 어떻게 만들 수 있습니까?
“a3″을 만들려면 “a1” + “a2″를 “a3″에 할당하기만 하면 됩니다.

이제 한 가지 더 해봅시다.
저는 보통 데이터를 요약하기 위해 많은 합계/평균/가중치를 사용합니다.
평균을 내자.
“a1″과 “a2″의 평균은 (a1+a2)/2로 볼 수 있습니다.
파이썬도 똑같습니다.

네 가지 산술 연산을 계속하면 됩니다.
예를 들어 예상한 대로 a1과 a2의 비율을 보려면 다음과 같이 작성합니다.

이제 약간 더 어려운 파생 변수를 만들어 보겠습니다.
sepal_length가 4.5보다 클 때 통과한다고 가정합니다.

그러면 어떤 조건을 갖추어야 합니까?
그냥 보면 ‘sepal_length’ >= 4.5임을 알 수 있습니다.
위의 조건을 주기 위해서는 조건문이 필요하며 Numphy 패키지의 where() 조건문으로 쉽게 표현할 수 있다.
기본 형식은 일반적인 Excel if 문과 동일합니다.
엑셀: if(조건, 참이면 값, 거짓이면 값)
Python: np.where(조건, true인 경우 값, false인 경우 값)으로 표현됩니다.
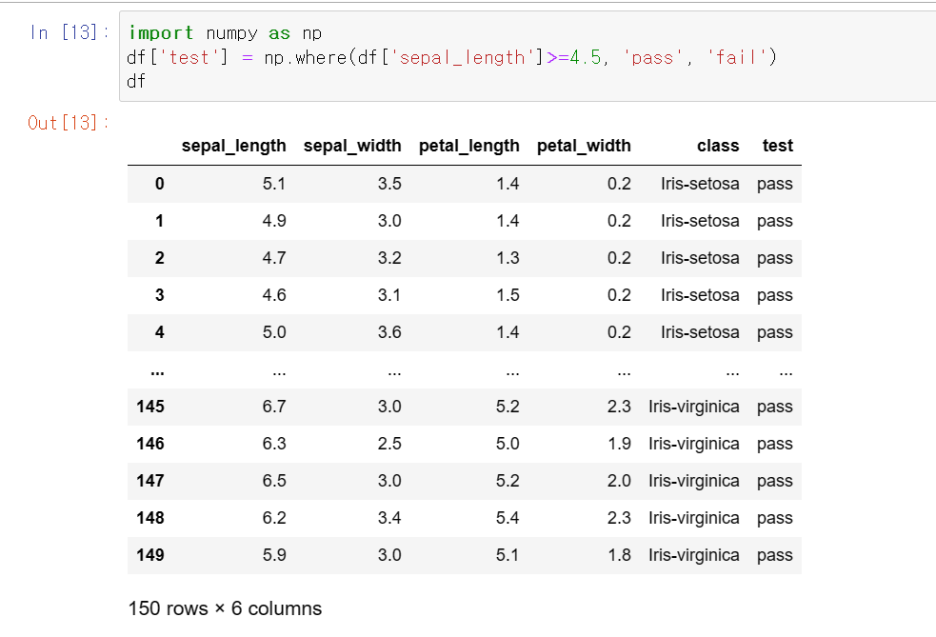
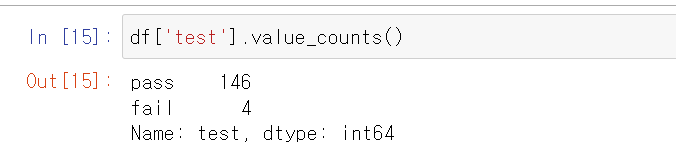
위의 결과가 어떻게 나왔는지 .value_counts() 함수로도 확인할 수 있습니다.
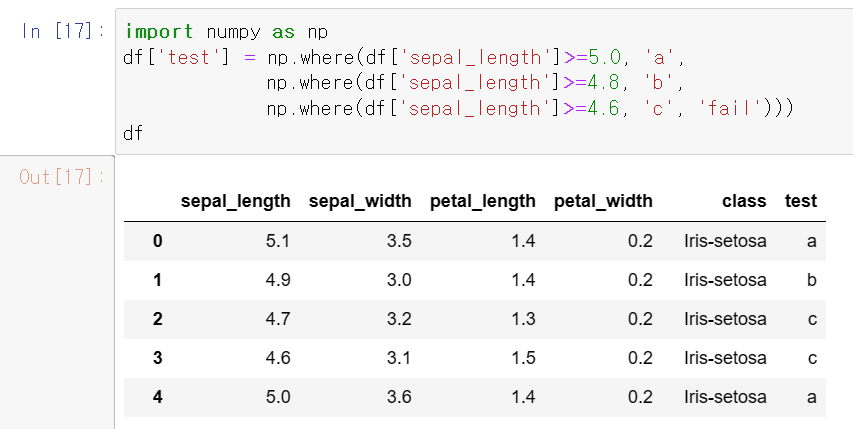
그렇다면 조건이 여러 개인 경우에는 어떻게 될까요?
엑셀에서는 if(condition, true, if(condition, true, false)) 형태로 표현하는데 조건이 복잡해지면 matching()은 눈이 아프다.
그러나 파이썬은 동일합니다. 가 포함되어 있는 한 끝에 괄호를 삽입해야 합니다.
익숙한 엑셀처럼 보면 문법이 정말 똑같다는 것을 알 수 있습니다.
df(‘test’) = np.where(df(‘sepal_length’)>=5.0, ‘a’, np.where(df(‘sepal_length’)>=4.8, ‘b’,np.where(df(‘ sepal_length’)>=4.6, ‘c’, ‘실패’)))
마지막으로, .isin() 함수는 조건을 지정하거나 여러 번 반복할 때도 사용할 수 있습니다.
.isin()에 넣을 값을 지정하면 쉽게 처리할 수 있습니다.
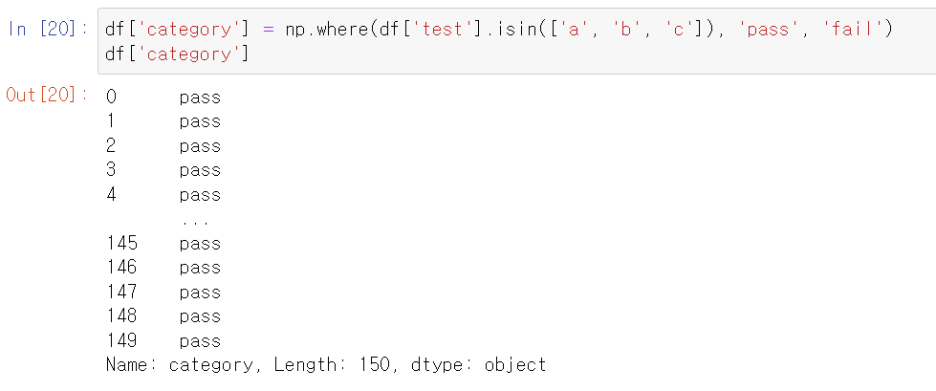
기억하기 가장 쉬운 방법은 다음과 같습니다.

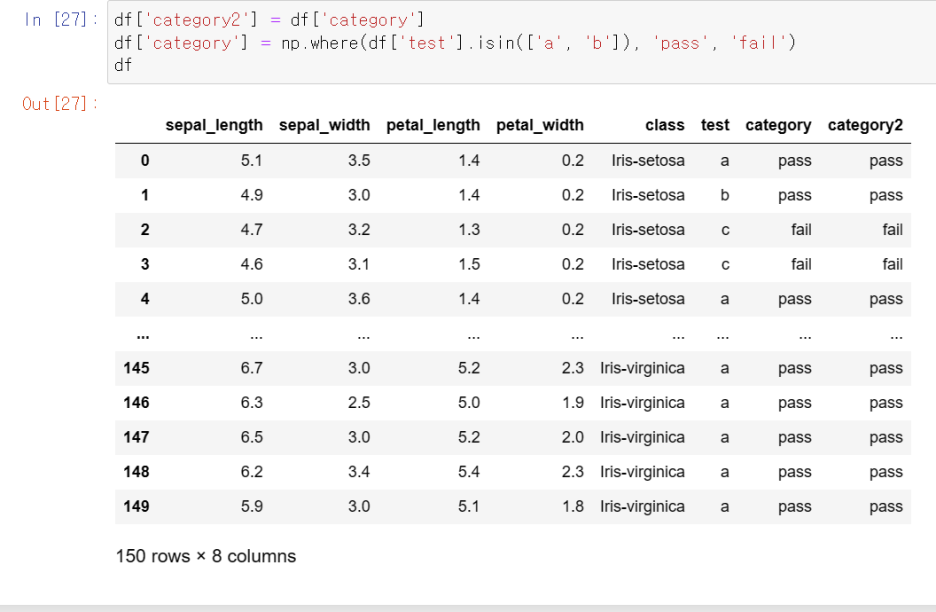
하지만 이 경우 문제가 발생합니다.
범주 값은 범주 2와 연관되어 있기 때문에 범주 값이 변경됨에 따라 서로 관련되어 함께 변경됩니다.
연결이 끊긴 상태에서는 Category가 변경되더라도 Category2는 변경되지 않아야 합니다.
불행히도 보시다시피 상황이 변경되었습니다.
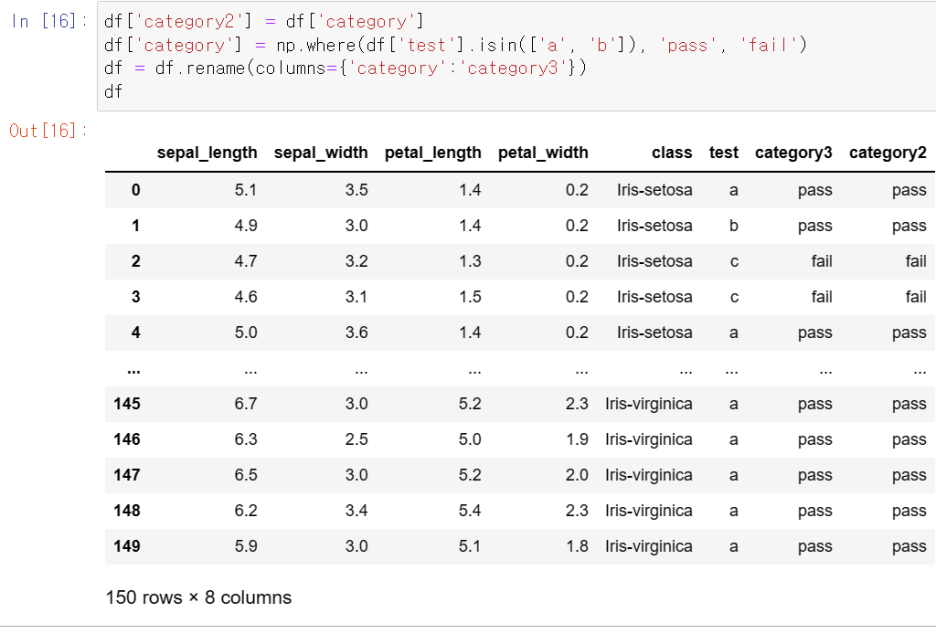
대신 쉬운 방법이 있습니다.
.rename() 함수를 사용하십시오.
.rename(columns = {기존 변수명: 변경된 변수명})다음과 같이 변경된 것을 볼 수 있습니다.
대표사진 삭제
사진 설명을 입력하세요.
파생 변수/변수 이름을 변경하는 방법을 배웠습니다.
다음으로 데이터 정렬에 대해 알아보겠습니다.